

AI has generated a lot of excitement in the maritime world, but cutting through the hype to find practical, high-value applications is not always straightforward. At Seaber, we believe the most impactful uses of Large Language Models (LLMs) right now are not magic “agents” running the business; they’re tools that help people work faster and make better decisions by solving long-standing data problems.
In the last months, we’ve introduced three new LLM-powered features that address exactly these challenges:
- Cargo dictation and automatic form filling
- Spreadsheet data normalization
- Port and commodity name mapping in external API data
All three share the same goal: turning unstructured or inconsistent information into clean, actionable, system-ready data.
Let’s dive into each of them.
1. Voice-to-cargo: dictate a cargo and turn it instantly into structured data
Chartering managers often work on the move; between calls, reviewing lists, checking the market, talking to brokers. Many have told us: “I just want to quickly capture a potential cargo without typing everything out.”
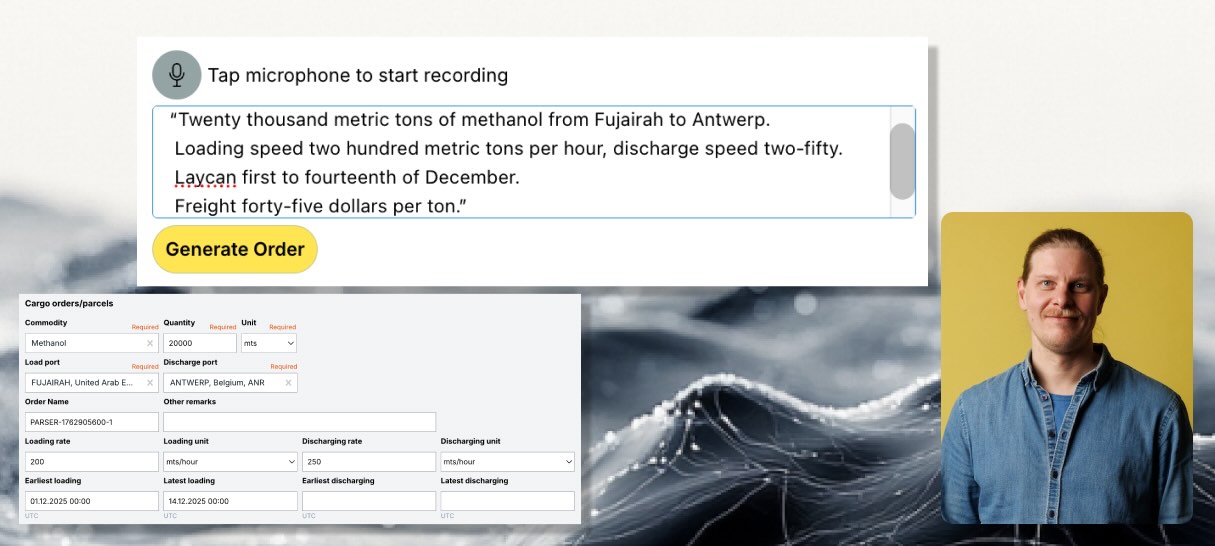
Our new cargo dictation tool solves exactly that. Whether on mobile or desktop, a user can simply speak:
“Twenty thousand metric tons of methanol from Fujairah to Antwerp.
Loading speed two hundred metric tons per hour, discharge speed two-fifty.
Laycan first to fourteenth of December.
Freight forty-five dollars per ton.”
Our LLM transcribes and interprets the spoken sentence, extracts every relevant datapoint, and automatically fills in the cargo form inside Seaber. The user simply checks the fields and saves.
This does two things immediately:
- Reduces manual entry time (especially on mobile, where typing is slow)
- Eliminates formatting errors or missing fields
And as soon as the cargo is saved, the system can automatically:
- suggest candidate vessels in your fleet
- highlight voyages where the cargo could be included
- show potential TCE impacts
One short dictation becomes a fully evaluated opportunity in just seconds.

2. Automatic normalization of messy spreadsheets
In real operations, cargo lists rarely come in a clean, machine-readable format. Teams share spreadsheets with:
- inconsistent column names
- different units
- merged cells
- human typos
- partial details
- changing templates across departments
Our new LLM-based spreadsheet normalizer allows users to upload any spreadsheet (no matter how chaotic) and have it automatically interpreted and mapped to Seaber’s internal cargo schema. The LLM model is self-hosted to ensure privacy of sensitive data.
Examples include:
- Market cargo lists shared in Teams/Email
- Shared internal “potential cargo” spreadsheets
- Previous cargo compatibility charts
- Congestion lists
- Any ad-hoc operational sheet that contains valuable data
Once uploaded, the LLM:
- reads the sheet
- infers the meaning of each column
- normalizes commodity names, ports, units, laycans, and rates
- converts it into clean structured data
- inserts it into the system for verification
This replaces hours of manual cleanup with a simple upload-and-confirm workflow.
3. Normalizing port and commodity names from external APIs
Even when data comes from a structured API, naming is rarely consistent. One provider may use “Fujairah”, another “FOJ”, another “Port of Fujayrah”. Commodities are even messier: “Methanol”, “MEOH”, “Methylic Alcohol”, “MeOH (Bulk)”.
Our LLM-powered alias mapper continuously cleans and aligns incoming data from external sources by:
- normalizing spelling variations
- recognizing synonyms
- mapping API values to internal Seaber definitions
- highlighting uncertain or ambiguous matches
Users remain in control: they can review, validate, or reject these mappings. Transparency is built in, and every assumption the model makes is visible to the user.
This ensures that external data streams can be consumed reliably without building and maintaining huge hard-coded dictionaries.
Why we started with these three use cases
There is a lot of discussion around “agentic AI” and complex autonomous workflows. Those will have their place, especially in operational automation. But when we looked at the biggest, clearest sources of value today, the answer was obvious:
- The maritime industry runs on unstructured, inconsistent, messy data
→ LLMs are uniquely suited to turn that into structured data.
- Data quality is the biggest bottleneck for automation and optimization
→ By solving naming, formatting, and interpretation problems at the source, we enable better calculations, better scheduling suggestions, and more accurate TCE insights.
- These tools enhance, not replace, human decision-making
→ Every LLM step in our system includes a validation layer. Users stay in full control.
- The ROI is immediate
→ These features remove friction in daily workflows that everyone in chartering, operations, and scheduling experiences.
LLMs as the glue between humans, data, and systems
The real promise of LLMs in maritime operations is not in replacing people. It’s in connecting the way humans naturally work (voice notes, spreadsheets, emails) with the strict data requirements of digital systems.
These new features are only the beginning. We’re continuing to explore AI-powered tools that:
- reduce manual work
- improve data consistency
- support real-time planning
- surface opportunities faster
- and enhance decision-making in complex scheduling environments
At Seaber, our philosophy remains simple: Use AI where it brings clear, practical, measurable value, and always keep the user in control.